「開発途中のテスト用サイトが、いつの間にかGoogle検索の設定結果に出てきてしまった😱」
これはWeb開発やブログ立ち上げ時によくある重大な失敗(ミス)の一つです。
中途半端なレイアウトのページや、テスト用のダミーテキスト(Lorem ipsumなど)が検索結果の全世界に公開されてしまうのは、絶対に避けたい事態ですよね。
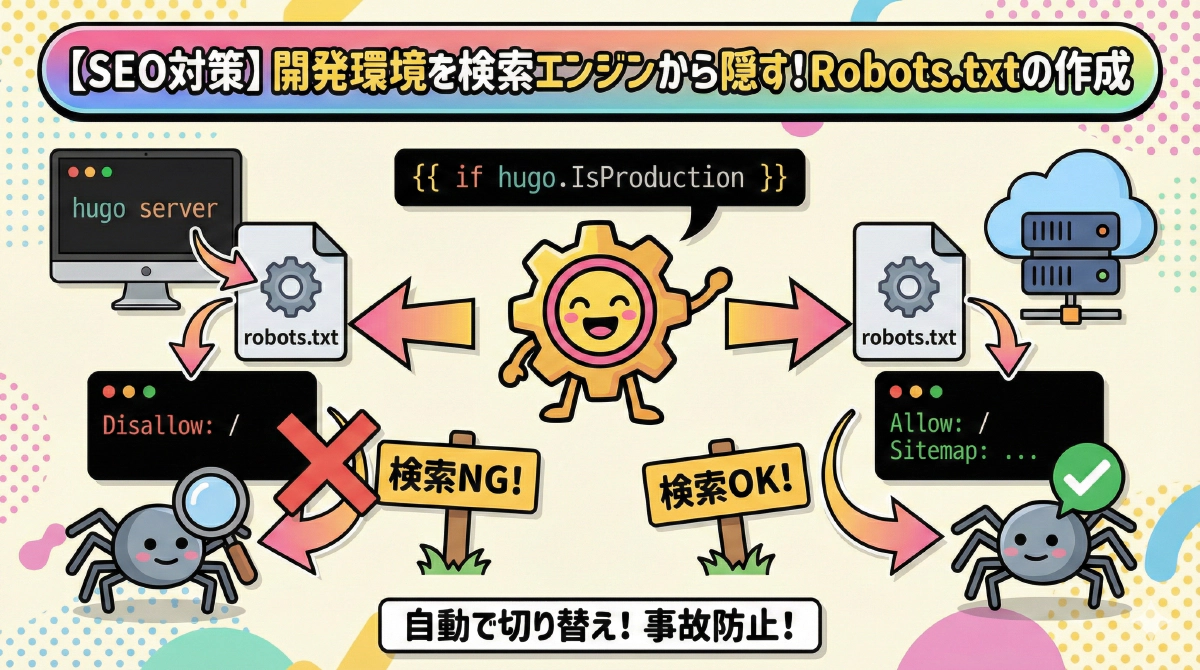
Hugoなら、テンプレート(layouts)にたった1つのファイルを作るだけで、「本番環境(Production)は検索を許可するが、それ以外(開発・テスト環境)は検索エンジンに対してクロールを拒否する」 というRobots.txtの切り替えを自動で行うことができます。
1. robots.txt とは?
検索エンジンのロボット(クローラー)に対して、「ここのページは見ていいよ」「ここは見ちゃダメだよ」と指示するためのテキストファイルです。
サイトのルート(https://example.com/robots.txt)に置かれます。
2. 実装方法
layouts/robots.txt というファイルを新規作成し、以下のコードをコピペしてください。
User-agent: *
{{ if hugo.IsProduction -}}
Allow: /
Sitemap: {{ "sitemap.xml" | absURL }}
{{ else -}}
Disallow: /
{{ end -}}
たったこれだけです!
コードの解説
User-agent: *: すべての検索エンジンロボットに対する指示です。{{ if hugo.IsProduction }}:- ここが肝です。「今ビルドしている環境は本番環境 (production) か?」を判定します。
- 本番環境なら:
Allow: /(全ページ許可)とサイトマップの場所を出力します。Sitemap: ...の行は、検索エンジンに「サイトマップはここだよ」と教えるための記述です。
- それ以外なら:
Disallow: /(全ページ拒否)を出力します。
3. どうやって確認するの?
ローカルサーバー (開発環境) の場合
hugo server で起動している時は、開発環境扱いになります。
ブラウザで http://localhost:1313/robots.txt にアクセスしてみてください。
User-agent: *
Disallow: /
と表示されていれば成功です!検索エンジンはこのサイトを無視します。
本番環境の場合
サーバーにデプロイする際、通常は環境変数などで hugo --environment production としてビルドされます(NetlifyやVercelなどのホスティングサービスではデフォルトでそうなっています)。
その場合、生成される robots.txt はこうなります:
User-agent: *
Allow: /
Sitemap: https://your-site.com/sitemap.xml
これで、本番サイトだけが正しく検索エンジンにインデックスされるようになります。
4. サイトマップ (sitemap.xml) の連携と最適化
さて、先ほどのコードの中に Sitemap: {{ "sitemap.xml" | absURL }} という行がありました。
これは**「うちのサイトの全ページリスト(サイトマップ)はここにあるので、クロールの参考にしてください」**と検索エンジンにお知らせする非常に重要な記述です。ロボットはこの道しるべを頼りに、効率よくサイト内の奥深くまでインデックスを行ってくれます。
Hugoはデフォルトの設定でもビルド時に自動で sitemap.xml を生成してくれますが、サイト全体のクロール頻度(週に1回更新するかどうか等)や優先度をコントロールすることで、巡回効率をさらに高めることができます。
hugo.toml でのサイトマップ全体設定
プロジェクト直下の hugo.toml を開き、末尾に以下の設定を追加しましょう。
# -----------------------------------------------------------------------------
# サイトマップ設定 (Sitemap)
# -----------------------------------------------------------------------------
[sitemap]
changefreq = "weekly" # ページの更新頻度 (always, hourly, daily, weekly, monthly, yearly, never)
filename = "sitemap.xml"
priority = 0.5 # 優先度 (0.0 から 1.0)
これがサイト全体の「デフォルト値」になります。
個別記事ごとに設定を変える場合 (フロントマター)
「この記事はすごく重要だからもっと頻繁に見に来てほしい!」という場合は、記事ごとのフロントマター(先頭の設定エリア)で、上書き指定することも可能です。
+++
title = 'とても重要な記事'
date = 2026-03-01T00:00:00+09:00
[sitemap]
changefreq = "daily"
priority = 0.8
+++
環境ごとのアクセス制御で安全なサイト運営を
本番への自動デプロイ設定をしていると、生成されたURLが意図せずクローラーに見つかってしまうことは多々あります。layouts/robots.txt を設定しておくだけで、開発中の無防備な状態がインデックスされる事故を未然に防ぐことができます。
また、robots.txt の中で正しく Sitemap の場所を宣言し、hugo.toml で更新頻度(changefreq)を制御することで、検索エンジンのクローラーに優しく効率的なサイト構造が出来上がります。
非常に地味な設定に見えますが、サイトの評価(SEO)を守り、情報を安全に管理する上でサイト公開前には「必須」と言っても過言ではない設定です。確実に追加しておきましょう!